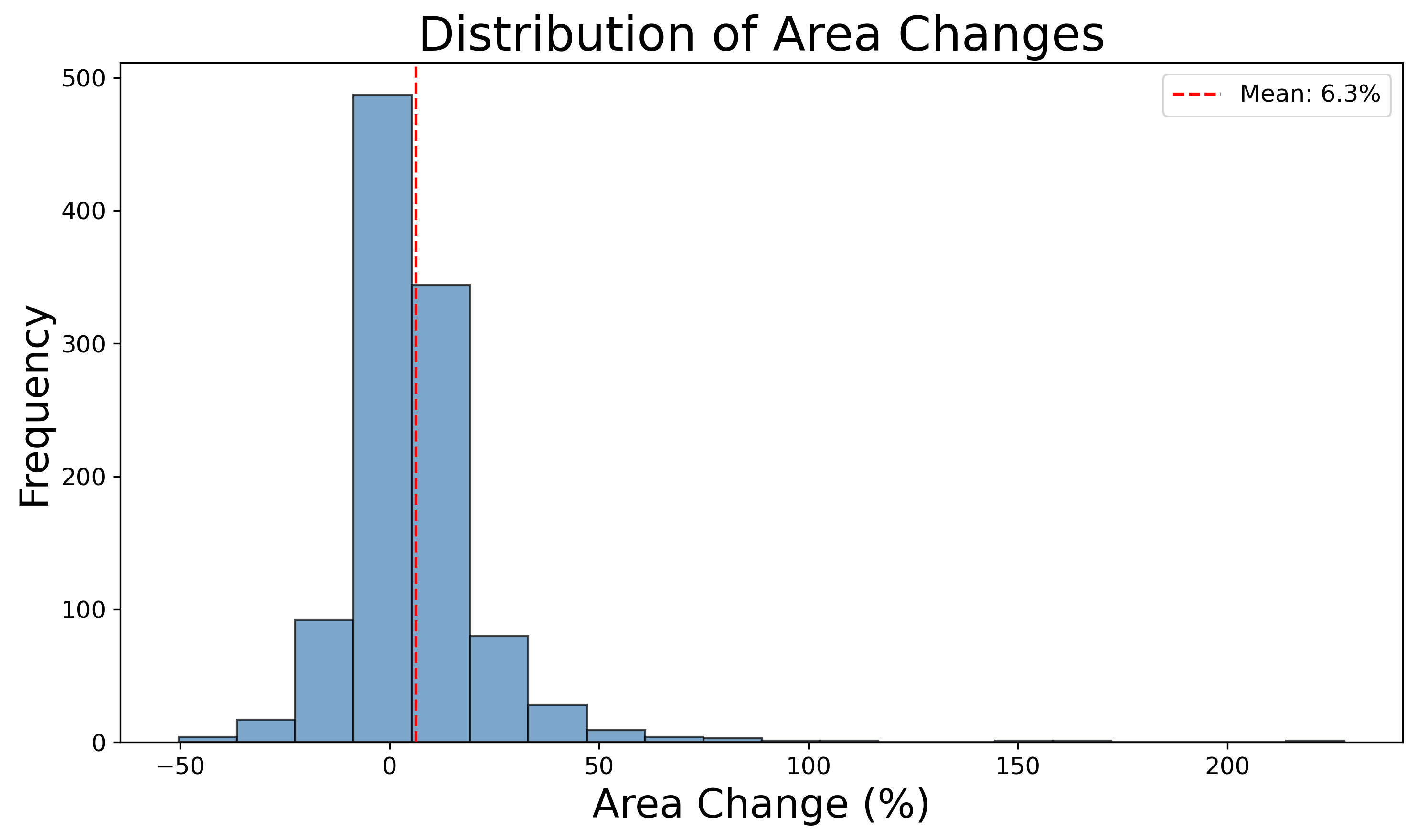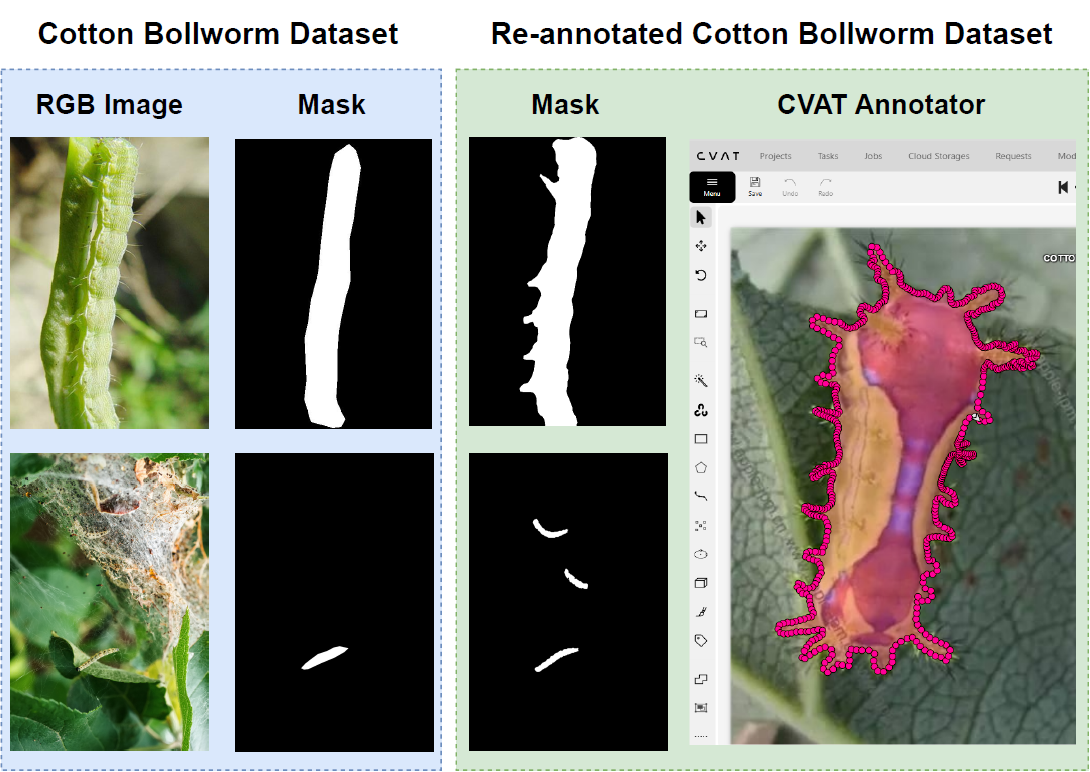
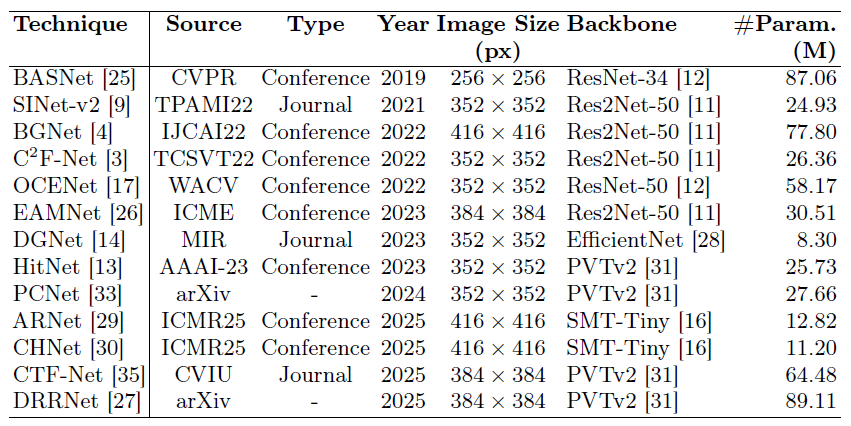
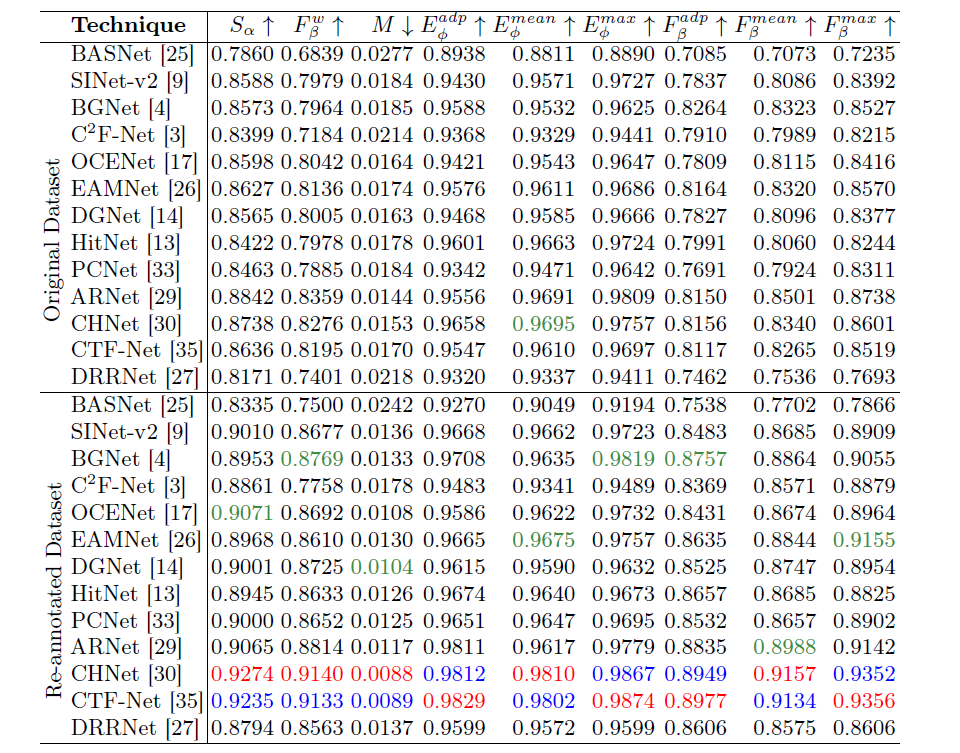
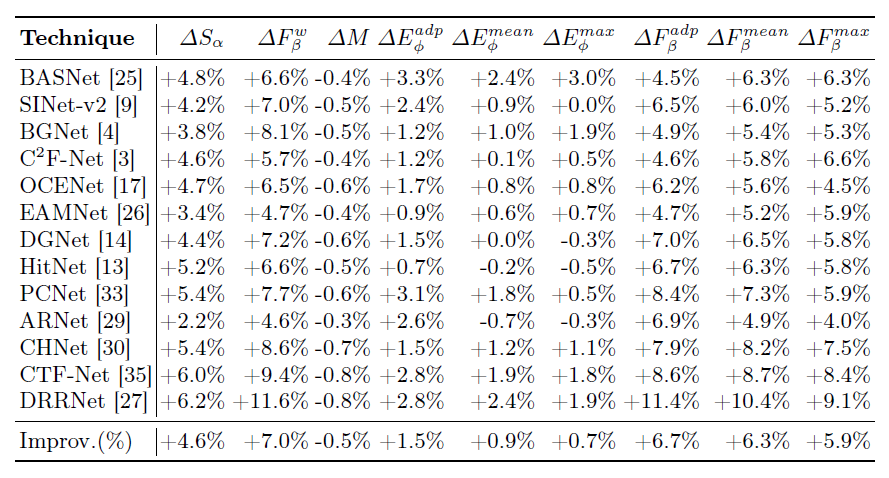
This paper presents an in-depth study on the impact of high-quality, comprehensive annotations on camouflaged object detection (COD) performance. We evaluate 13 state-of-the-art COD models trained on original annotations versus a re-annotated version created under stricter, more consistent guidelines using the Cotton Bollworm dataset. Experimental results demonstrate that enhanced annotation quality significantly improves both Intersection over Union (IoU) scores and instance recall, reducing undetected camouflaged objects by an average of 4.6% in Structure-measure and 7.0% in weighted F-measure. The re-annotation process identified 1.4% additional instances with 6.3% average area refinement, primarily through boundary precision improvements and detection of previously missed instances. These findings underscore the crucial role of precise annotations in advancing COD performance and validate the data-centric AI paradigm, suggesting that systematic annotation refinement should be prioritized in computer vision pipelines. The re-annotated dataset will be made publicly available to support future research.
















.png)
.png)

.png)



_comparison.png)
_comparison.png)

_comparison.png)